Data Loader Instrumentations
graphql-kotlin-dataloader-instrumentation is set of custom Instrumentations
that will calculate the right moment to dispatch KotlinDataLoaders across single or batch GraphQL operations.
These custom instrumentations follow the similar approach as the default DataLoaderDispatcherInstrumentation
from graphql-java, the main difference is that regular instrumentations apply to a single ExecutionInput aka GraphQL Operation,
whereas these custom instrumentations apply to multiple GraphQL operations (say a BatchRequest) and stores their state in the GraphQLContext
allowing batching and deduplication of transactions across those multiple GraphQL operations.
By default, each GraphQL operation is processed independently of each other. Multiple operations can be processed together as if they were single GraphQL request if they are part of the same batch request.
The graphql-kotlin-dataloader-instrumentation module contains 1 custom DataLoader instrumentation.
Dispatching by synchronous execution exhaustion
The most optimal time to dispatch all data loaders is when all possible synchronous execution paths across all batch operations were exhausted. Synchronous execution path is considered exhausted (or completed) when all currently processed data fetchers were either resolved to a scalar or a future promise.
Let's analyze how GraphQL execution works, but first lets check some GraphQL concepts:
DataFetcher
Each field in GraphQL has a resolver aka DataFetcher associated with it, some fields will use specialized DataFetchers
that knows how to go to a database or make a network request to get field information while most simply take
data from the returned memory objects.
Execution Strategy
The process of finding values for a list of fields from the GraphQL Query, using a recursive strategy.
Example
You can find additional examples in our unit tests.
- Queries
- Execution
query Q1 {
astronaut(id: 1) { # async
id
name
missions { # async
id
designation
}
}
}
query Q2 {
nasa { #sync
astronaut(id: 2) { # async
id
name
missions { # async
id
designation
}
}
address { # sync
street
zipCode
}
phoneNumber
}
}
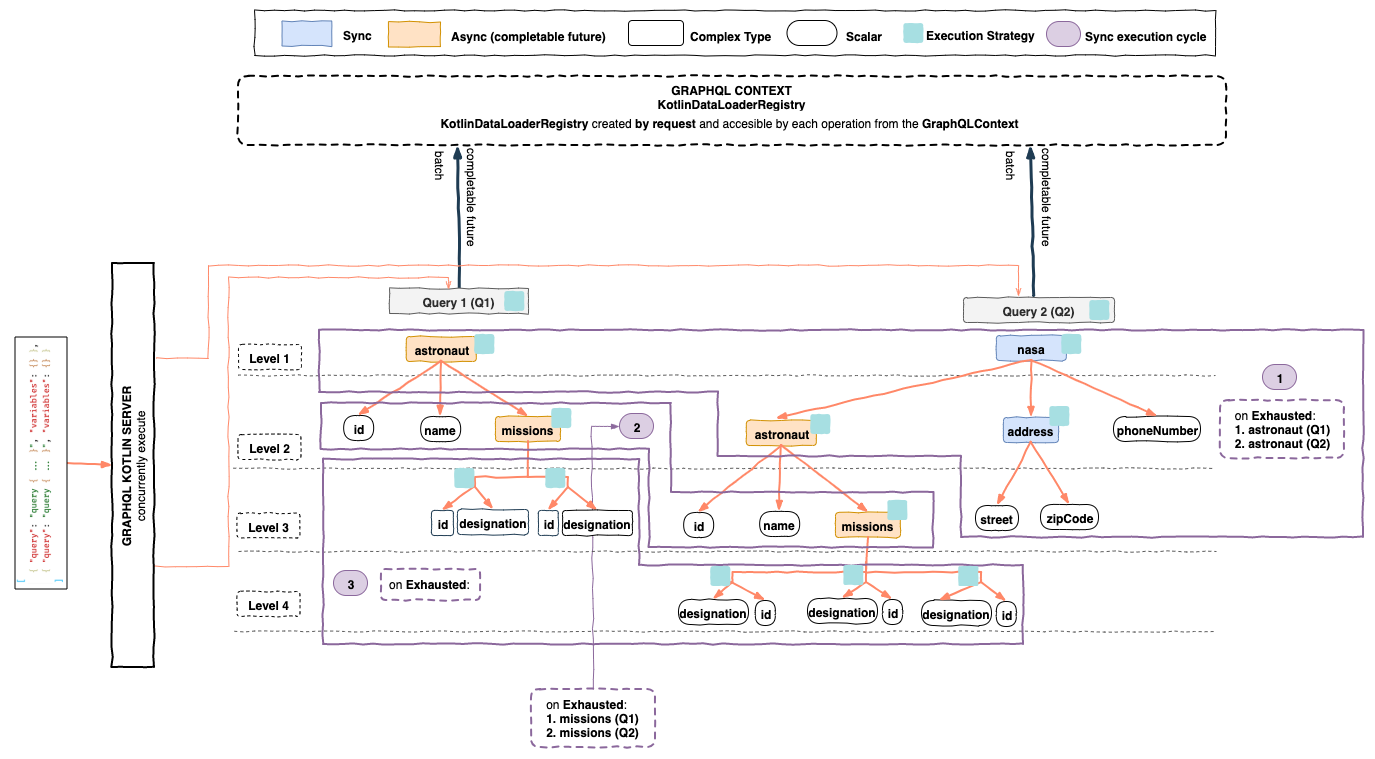
The order of execution of the queries will be:
for Q1
- Start an
ExecutionStrategyfor therootfield of the query, to concurrently resolveastronautfield.astronautDataFetcher will invoke theAstronautDataLoaderand will return aCompletableFuture<Astronaut>so we can consider this path exhausted.
for Q2
- Start an
ExecutionStrategyfor therootfield of the query, to concurrently resolvenasafield.nasaDataFetcher will synchronously return aNasaobject, so we can descend more that path.
- Start an
ExecutionStrategyfor thenasafield of therootfield of the query to concurrently resolveastronaut,addressandphoneNumber.astronautDataFetcher will invoke theAstronautDataLoaderand will return aCompletableFuture<Astronaut>so we can consider this path exhaustedaddressDataFetcher will synchronously return anAddressobject, so we can descend more that path.phoneNumberDataFetcher will return a scalar, so we can consider this path exhausted.
- Start an
ExecutionStrategyfor theaddressfield of thenasafield to concurrently resolvestreetandzipCode.streetDataFetcher will return a scalar, so we can consider this path exhausted.zipCodeDataFetcher will return a scalar, so we can consider this path exhausted.
At this point we can consider the synchronous execution exhausted and the AstronautDataLoader has 2 keys to be dispatched,
if we proceed dispatching all data loaders the execution will continue as following:
for Q1
- Start and
ExecutionStrategyfor theastronautfield of therootfield of the query to concurrently resolveid,nameandmissionfields.idDataFetcher will return a scalar, so we can consider this path exhausted.nameDataFetcher will return a scalar, so we can consider this path exhausted.missionsDataFetcher will invoke theMissionsByAstronautDataLoaderand will return aCompletableFuture<List<Mission>>so we can consider this path exhausted.
for Q2
- Start and
ExecutionStrategyfor theastronautfield of thenasafield of the query to concurrently resolveid,nameandmissionfields.idDataFetcher will return a scalar, so we can consider this path exhausted.nameDataFetcher will return a scalar, so we can consider this path exhausted.missionsDataFetcher will invoke theMissionsByAstronautDataLoaderand will return aCompletableFuture<List<Mission>>so we can consider this path exhausted.
At this point we can consider the synchronous execution exhausted and the MissionsByAstronautDataLoader has 2 keys to be dispatched,
if we proceed dispatching all data loaders the execution will continue to just resolve scalar fields.
Usage
In order to enable batching by synchronous execution exhaustion, you need to configure your GraphQL instance with the GraphQLSyncExecutionExhaustedDataLoaderDispatcher.
val graphQL = GraphQL.Builder()
.doNotAddDefaultInstrumentations()
.instrumentation(GraphQLSyncExecutionExhaustedDataLoaderDispatcher())
// configure schema, type wiring, etc.
.build()
This data loader instrumentation relies on a global state object that needs be stored in the GraphQLContext map
val graphQLContext = mapOf(
SyncExecutionExhaustedState::class to SyncExecutionExhaustedState(queries.size) {
dataLoaderRegistry
}
)
graphql-kotlin-spring-server provides convenient integration of batch loader functionality through simple configuration.
Batching by synchronous execution exhaustion can be enabled by configuring following properties:
graphql:
batching:
enabled: true
strategy: SYNC_EXHAUSTION
Multiple data loaders per field data fetcher
There are some cases when a GraphQL Schema doesn't match the data source schema, a field can require data from multiple sources to be fetched and you will still want to do batching with data loaders.
DispatchIfNeeded
graphql-kotlin-dataloader-instrumentation includes a helpful extension function of the CompletableFuture class
so that you can easily instruct the previously selected data loader instrumentation
that you want to apply batching and deduplication to a chained DataLoader in your DataFetcher (resolver).
Example
type Query {
astronaut(id: ID!): Astronaut
}
# In the data source, let's say a database,
# an `Astronaut` can have multiple `Mission`s and a `Mission` can have multiple `Planet`s.
type Astronaut {
id: ID!
name: String!
# The schema exposes the `Astronaut` `Planet`s, without traversing his `Mission`s.
planets: [Planet!]!
}
type Planet {
id: ID!
name: String!
}
The Astronaut planets data fetcher (resolver) will contain the logic to chain two data loaders,
first collect missions by astronaut, and then, planets by mission.
DataLoaders
For this specific example we would need 2 DataLoaders
- MissionsByAstronaut: to retrieve
Missions by a givenAstronaut. - PlanetsByMission: to retrieve
Planets by a givenMission.
Fetching logic
class Astronaut {
fun getPlanets(
astronautId: Int,
environment: DataFetchingEnvironment
): CompletableFuture<List<Planet>> {
val missionsByAstronautDataLoader = environment.getDataLoader("MissionsByAstronautDataLoader")
val planetsByMissionDataLoader = environment.getDataLoader("PlanetsByMissionDataLoader")
return missionsByAstronautDataLoader
.load(astronautId)
// chain data loader
.thenCompose { missions ->
planetsByMissionDataLoader
.loadMany(missions.map { mission -> mission.id })
// extension function to schedule a dispatch of registry if needed
.dispatchIfNeeded(environment)
}
}